Recently we were asked by a friend if we could help with a text recognition problem. He had a pdf of a handwritten book that he wanted typed as computer readable text. While we didn't have much experience with optical character recognition (OCR), we were interested and looked into what can be done.
- Preprocessing
- Segmentation
- Recognition
- Postprocessing
Preprocessing includes resizing the input into an usable resolution and binarization of the images. The segmentation includes page layout analysis and detecting lines of written text. The Recognition is done on entire lines instead of words or characters and the post processing includes putting the data/results in a presentable format and possible fix the mistakes done by the recognition. We found a popular software for OCR is OCRopus, which implements methods for most of the steps described. Here is one of the pages we were working on:

Now it's important to note that the text we had contained both latin and non-latin characters. Which is why all pre-trained models that come with OCRopus would not yield usable results. After trying some of them we decided to train or own model. We found a great tutorial on how to train custom OCRopus models here. The preprocessing and segmentation steps were working expected.
Since we were happy with our segmentation, we keept it and created a '.gt.txt' file for every segmented '.png' file.
Our text contains both latin and non-latin characters. And because we don't know about the non-latin characters we labeled them as '?'.
A model that knows how to mark all non-latin characters is also of value to us.
As a start we created ground truth data for one page and trained on that.
This is how the output of the training process can look like.
24827 71.72 (1649, 48) temp/0001/010003.bin.png
TRU: u'(im heil. Buche), so spricht (der heil. Lehrer). (Ich habe dieses Wort nach dem Vorgange west'
ALN: u'(im heil. Buuche), so spricht (der heil. Lehrer). (Ich habe dieses Wort ach dem VVorgange west'
OUT: u'(inm hel. Buuche), s gricht (der heil. Lchrer. ch hbe dieses Wort ah. denmm ?rgnnge est'
For every iteration we can see the ground truth label (TRU) the output of the current state of the model (OUT) and a variant ot the model output which is used for the training (ALN). The tutorial we learned from suggested having about 30,000 iterations, which even tough we had much fewer training samples we still decided to do.
Here's an example of what our model learned:
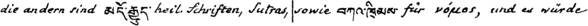
die ondern sind ???? heil chriten, utras, sowie ??????? für oos, nd es würde-
There's more details on what we did and how we did it as well as the trained model on our github. Our next step will be to decide if we want to create an actual proper training set including the non-latin characters that we can run on the entire book.
Keine Kommentare:
Kommentar veröffentlichen